The Scholar in
the Digital Library
John Unsworth
Institute for Advanced Technology in the Humanities (IATH)
University of Virginia
April 6, 2000
My purpose here is to consider, in abstract, almost generic terms, what it is that scholars now do and what they will be doing in the digital library, to ask what tools they now have and what tools they must have in order to do those things, and to speculate very briefly on how libraries and library collections are changing and will change further in response to these scholarly activities. This will be, I'm afraid, an exercise in not overlooking the obvious: some of the simplest things that people want to be able to do are still fairly difficult problems for computers; others are more difficult socially or politically than technically: in fact, my thesis here is that we shouldn't allow ourselves to go on to complicated problems until we've better addressed the most basic ones. At the same time, I have some interest in thinking about how mass-market (e-commerce) tools and techniques can be brought to bear on humanities research. At this point in the development of the Web, there are tools in common commercial use that could significantly enhance the effectiveness of scholarly research in the digital library, if only they were brought to bear on Schopenhauer rather than shopping. Much of the discussion, though, will focus on the different ways in which scholars will find text and images in the digital library, and on that note, I should say that many of the examples I use here were themselves found through what remains, in my opinion, the most advanced and effective scholarly finding aid--that biochemical search engine called "colleagues": Johanna Drucker, Chris Jessee, Matt Kirschenbaum, Worthy Martin, Willard McCarty, Jerome McGann, Daniel Pitti, and John Price-Wilkin all contributed points, pointers, or perspectives in what follows.
Scholar?
For the purposes of this discussion, "scholar" means a researcher in the humanities whose work is heavily dependent on both text and images, who works with primary resources (and/or their digital representations), and who produces scholarly publications (probably, but probably not exclusively, in electronic form). Though we may be inclined to think that the core disciplines of the humanities are exclusively textual in their interests, in practice they turn out to be almost equally interested in images.
Digital Library?
A "digital library," in this discussion, means something more than the Web at large: it means an intentional collection of digital resources assembled, catalogued, indexed, preserved, and presented to serve the needs of scholarship. The digital library can exist outside the university--and increasingly, we will see them come into being in the form of the archives of corporations (Corning, for example, has mountains of historical data about its own operations, its own research, its own innovations)--but even in those cases, the purpose is more or less the same (Corning wants their engineers to be able to bring past experience to bear on current research agendas). To be called a "digital library" in the sense that I mean it here, the institution in question would have to present full-text (and full-image) resources, not just finding aids that point to boxes on a shelf--not that these aren't very important: they're simply not what I'm talking about here.
In?
I think I should also specify what the word "in" means when I talk about the scholar "in" the digital library. It might very well mean physically present in the library building, especially if there is a workspace there that hosts collaboration, houses staff support, or provides specialized equipment. It might also mean that the scholar is "in" the collection, as a remote user, and it might imply a kind of workspace that is itself "in" library computer systems, though perhaps technically "adjacent" to library digital collections. For the scholar, being "in" the library means being able to work with digital collections, possibly collaborating with others working on the same material, and perhaps being able to publish into, or out of, those collections.
And?
Now that we have the "scholar" "in" the "digital library," what's she doing there? What are the researcher's major modes of intellectual access to information in this environment and what do we see as the functional primitives underlying scholarship in the digital library, or indeed, scholarship in general? Discovery, labeling, counting, comparison, annotation, representation: this is the beginning of a list, not by any means exhaustive (and in any case, who's to say that the list is closed or consistent over time or across disciplines?). I'd like to look at the first and most important of these scholarly primitives --discovery--as it occurs in relation to digital images and electronic texts today. The others are important to consider and explore, but frankly, we haven't really progressed beyond the first step in the first primitive, so there's plenty still to talk about in the realm of discovery.
Finding text through other text:
This is the normal case (and generally speaking, the limit) for scholars in the digital library as it now exists. This kind of discovery begins with library catalogues and also search engines, inside and outside the library. It includes all of the searches of licensed electronic databases, electronic reference works, and the Web itself. Some interesting examples include Google, a very simple but remarkably effective search engine. If you install in your web browser the personal toolbar buttons from http://www.google.com/buttons.html you can highlight text on a page and hit the Google button to effect a search for the highlighted text string. The Google Scout button will tell you what other web pages are like the one you're looking at. That's the simplest kind of text-based text discovery mechanism that I know of right now, and it's the kind that most of us use most of the time, because it searches full-text indexes of a very large body of material. The down-side, as we all know, is that unstructured text searches return lots of irrelevant results, but let us not make the mistake that the hypertext theory crowd made when the Web came along, refusing for years to believe that this inferior implementation would really catch on. Our students use Google, I would be willing to bet, far more frequently than they use the library catalogue system. Why? Not because the information is better, or because the results are more relevant, but because the "library" is far, far larger and the process of initiating a search is one or two steps, not eight or ten.
By saying that, I don't mean to imply a fondness for unstructured data or irrelevant results: we all know that achieving the next step up in relevance requires more highly structured data and/or more intelligent software and/or more involvement on the part of the searcher, either in structuring the search terms or in iteratively refining a set of search results. But interesting mass-market examples of highly structured data are no longer as hard to come by as they used to be: just go shopping, and you'll find them. Interesting mass-market examples of more intelligent search software are also available--for example Northern Light (http://www.northernlight.com/), which clusters search results in topical folders (a search for "squid," returns 135,319 items sorted into folders labeled "Octopus & Squid," "Computer caches," "FreeBSD," "Swimming & diving," "Thai Food," "Parsing" and so on--suggesting, among other things, the futility of thesauri).
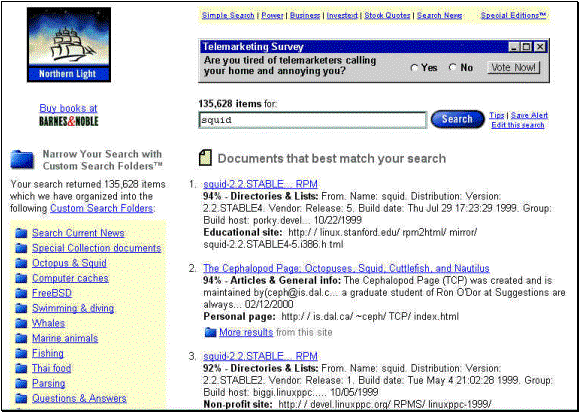
Northern Light is also interesting in that it searches both "special collections" (premium information sources) and the Wild Wild Web, and offers you your results separately or combined, as you like.
But closer to the topic at hand, library-based instances of interesting and effective text-for-text searching abound--for example, Making of America I (hereafter MOA1), which describes itself as "a thematically related digital library documenting American social history from the antebellum period through reconstruction" (personally, I think of MOA1 more as a thematic research collection than a library, but in the digital arena (IATH included) we generally experience this kind of scale-creep in naming: projects call themselves archives, collections call themselves libraries, and so on). MOA1 offers a set of forms (at http://moa.umdl.umich.edu/moa_adv.html or http://cdl.library.cornell.edu/moa/moa_adv.html) which you can use to perform Boolean searches, proximity searches, frequency searches (for example to find that, at the Michigan site, three works written between 1800 and 1925 contain the word "squid" at least four times and "virgin" at least three times; none do at the Cornell site), bibliographic searches, or index searches (for example, titles including the word "squid"--there are no books listed as being by, about, or titled "squid" in either collection, though mysteriously there is one work at Michigan that shows up when you search for the title word "Kraken," suggesting that a thesaurus might have been able to provide a squid-pro-quo here).

The problem with a collection such as MOA1, as wonderful as it is, and the problem with any of the thematic research collections at IATH, is that a collection is bounded--by its own logical and institutional structures--in ways we would hope the digital library will not be, in ways that producers of the collection will inevitably care about more than users do. Obviously, you can't have the same kind of structured access where the same structures don't exist, but even in the MOA1 (where the same logical structures do exist), it isn't possible to execute a single search across the institutional boundary between the Michigan and Cornell collections (not for lack of effort: as John-Price Wilkin of Michigan has told me: "Cornell and Michigan started with the intention of developing an interoperable environment for MOA1. In fact, we implemented a Z39.50 search across the collections during the funded period, but took it down because it was inefficient, misleading, aand unreliable. The problem in this area is that interoperability with materials like this is so badly supported" by any of the existing standards) . More generally, though, no single thematic research collection is going to contain all useful data on a subject or take responsibility for indexing and providing access to data in other collections elsewhere.
To facilitate that next step, in which one provides structured text searches across many collections not belonging to the same library or the same joint effort, is going to require further development of standards like Dublin Core, Z39.50, and others. This need is confirmed by the proposal for the Cheshire project (http://cheshire.lib.berkeley.edu/) at Berkeley, where the Making of America II (no relation to MOA1, the Michigan/Cornell project) is a participant (along with the Arts and Humanities Data Service (AHDS), the CURL (Consortium of University Research Libraries), and the Online Archive of California (OAC)) in a Cheshire-based NSF-JISC project, "Cross-domain Resource Discovery: Integrated Discovery and use of Textual, Numeric, and Spatial Data," under the joint management of Berkeley and the University of Liverpool. In the proposal for that project, the authors (Ray Larson and Paul Watry) point out that
The reality is . . . [that] repositories of recorded knowledge are only a small part of an environment with a bewildering variety of search engines, metadata, and protocols of very different kinds and of varying degrees of completeness and incompatibility. The challenge is to not only to decide how to mix, match, and combine one or more search engines with one or more knowledge repositories for any given inquiry, but also to have detailed understanding of the endless complexities of largely incompatible metadata, transfer protocols, and so on.
The proposal goes on to envision, instead,
a large population of users scattered around the globe who wish simultaneously to access the complete contents of thousands of archives, museums, and libraries, containing a mixture of text, images, digital maps, and sound recordings. Such a virtual library must be a networked-based distribution system with local servers responsible for maintaining individual collections of digital documents, which will conform to a specific set of standards for documentation description, representation, and communications protocols. . . . The Cheshire retrieval system . . . will enable coherent expressions of relationships among objects and collections, showing for any given collection superior, subordinate, related, and context collections. These are essential prerequisites for the development of cross-domain resource discovery tools, which will enable users to access diverse collections through a single interface.
(http://cheshire.sims.berkeley.edu/proposal.html)
The discovery of text through text is the scholarly activity that the digital library currently supports best, and clearly, we have work to do even there. For starters, scholars would prefer not to have to trade relevance for comprehensiveness in the discovery process: at the moment, we do. We can go to general-purpose search engines that index vast amounts of unstructured data, or we can find our way to specific collections, learn their characteristics and their functionality, and cobble together our results by searching in many places, using many tools. Larson and Watry hope to bring us something better, and I hope they do. I'd like a Google button searching a Cheshire index of the global digital library's squid-related resources and returning results to me in Northern Light folders, please.
Finding images through text:
The passage just quoted from the Cheshire proposal also suggests a second kind of "discovery" that scholars currently do--or really, are just beginning to do--in the digital library, namely the discovery of images through text. At the moment, this is done through catalogue records, controlled vocabulary, captions, and general descriptions. There are a number of examples of text-based searches of images, though they are less numerous than examples of text-based searches of text. Berkeley, Columbia, Duke, Tufts, Virginia, the Library of Congress, the New York Public Library, all host significant collections of digital images that are searchable using text-based queries. Some of these collections and search mechanisms also use special controlled vocabularies, another layer of the problem of cross-cutting access to digital library materials. The controlled vocabularies in question might include those described and cross-referenced in the Getty's "Crosswalk of Metadata Standards" (to be found on the Getty's Web site, at http://www.getty.edu/gri/standard/intrometadata/crosswsd.htm), which points out that
Each of these standards can be said to represent a different "point of view"––while Categories for the Description of Works of Art provides broad, encompassing guidelines for the information elements needed to describe an art object from a scholarly or research point of view, Object ID codifies the minimum set of data elements (ten in all) needed to protect an object from theft and illicit traffic. The CIMI Schema defines data elements for "deep" museum information. The FDA guidelines focus on architectural documents, while MESL and the VRA Core Categories provide data elements for both the object and its visual surrogate. [etc.].
My own favorite example of access to images through a text-based search using controlled vocabulary is, I confess, the Blake Archive's Image Search (found at
http://dazzle.village.virginia.edu/blake-search/image.html).
The Blake Archive's image search is, I think, an elegant demonstration of how SGML markup can support region-specific searches in a large image collection, leveraging editorial descriptions (and a controlled vocabulary) to deliver more accurate and relevant results than any image-recognition software now available could provide. But the Blake Archive's image search also points up the real problem with text-based image-searching, namely the local particularity of vocabularies. In order for text-based image searches to rise to what we might call the Cheshire-level of "Cross-Domain Resource Discovery," these vocabularies will have to be coordinated in some way, either through a kind of meta-thesaurus (mapping terms across perspectival vocabularies--and doing so in a way that's available to arbitrary search engines), or perhaps through some scholar-specific thesaurus that operates, in search situations, in the manner of a personal set of preferences or an individual vocabulary filter.
New research in the area of "scholarly preferences" is critical, and might produce far greater functional results, for individual scholars, than the much more difficult task of coordinating professional vocabularies and constructing inter-perspectival thesauri (though of course, these efforts will also take place, and should). Advertising sites now use cookies in (actually rather frighteningly) sophisticated ways to track your browsing and buying behavior across sites. Every page you visit that has an ad from doubleclick.net knows something about where you've been and what you've done at other sites with doubleclick ads. Would that bad thing be a good thing if instead of doubleclick, it were my own academic library that were collecting that information and trying to use it, not to sell me shoes, but to send me information from local collections that seemed relevant to my activity in the wider world? And combine that information with an analysis of the documents in my bookmarks and my history file, to produce a locally stored preference filter. Give me a Google button searching a Cheshire index of the global digital library's image-based squid-related resources (that's open sea, not open source) and returning results to me in Northern Light folders, please.
Finding images through images:
Intuitively, it would seem that the most natural way to search for images would be to use images themselves to formulate the query ("here's a picture of a squid: please find me other pictures of squid"). And indeed, there's been some interesting research in this area, though the applications I'm aware of are still fairly limited at the moment, offering only certain kinds of pattern or layout matching, and no ability to deal directly with the semantic content of visual material. The oldest example of this kind of discovery tool, I believe, is IBM's QBIC (Query By Image Content) software. You can see QBIC in action at the Hermitage Museum's web site, at:
http://www.hermitagemuseum.org/fcgi-bin/db2www/qbicSearch.mac/qbic?selLang=English
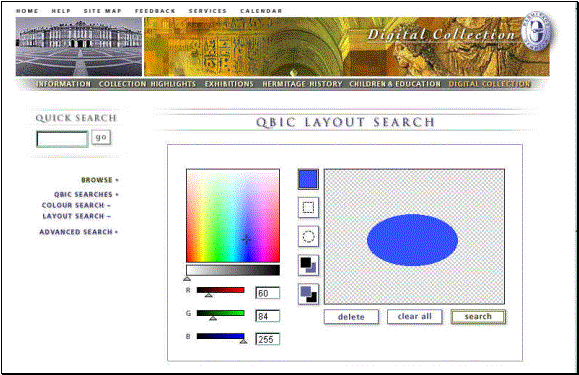
At this site, you can search images in one of two ways--by color-matching or by layout-matching. If you choose the former, pixels are classified against a color chart and then counted; if you choose the latter, color distribution in the picture is matched according to a grid the software's pre-processing imposes on all images alike.
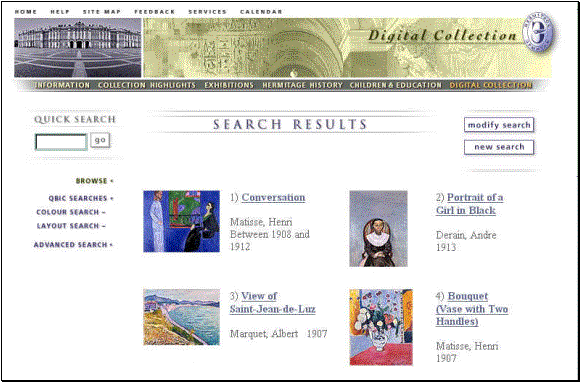
The results are interesting, but mostly because elements in the result-set seem so unlike one another: when we do a layout search for pictures having a central bluish oval, we get back, as our top-ranked results, Matisse's "Conversation" (OK, mostly blue, but nothing oval in sight), Derain's "Portrait of a Girl in Black" (blue background, but the only ovalish thing in the center is the girl, and she's in black), and Albert Marquet's " View of Saint-Jean-de-Luz" (not bad--a beach with an ovalish section of blue water--so why is this one third?). It's not easy to see why the pictures returned in response to this query are considered matches, and indeed, even when searches work better than this one did, scholars generally wonder what possessed the software designers to create QBIC, and who in the world wants to find pictures with central blue ovals, and for what reason. There is a rationale for QBIC, of course, namely that it gives us access to those aspects of image collections that a computer can readily identify by itself (histograms, locations in x-y coordinate space, etc.). I suppose there are people who find this useful--publications designers, perhaps--but I have yet to meet a scholar who thinks QBIC would be a useful discovery tool.
Another, more interesting example of image-based discovery of images is Blobworld (at http://elib.cs.berkeley.edu/photos/blobworld/). Blobworld's critical advance over QBIC (and other programs like it) is that, in pre-processing the images in its collection, it uses a segmentation algorithm to break images up into smaller regions that are coherent in color and texture. These smaller regions, or "blobs" are then matched against the user's query.

That query begins with the user selecting an image, which is then presented in its "blobworld" representation. The user chooses one or more blobs and weights things like color, texture, location, shape, background, and so on. Results are much better, from a semantic point of view, and what's better still is that the result set includes both the images and their blobworld representation, so you can see why an image matched the query, and you can use results as the basis of new queries.

You can also add keywords to the query, though the inventors of Blobworld warn that with the commercial (Corel) image set that Blobworld uses for this demo "a query using the keyword "planes" retrieves 144 images, more than half of which are pictures of animals on the plains. The keyword "plains" has just one match"--thereby reminding us that our culture's long pursuit of universal literacy isn't yet over.
The last example of image-based discovery of images that I'll mention is a project called Foureyes (http://www-white.media.mit.edu/~tpminka/photobook/foureyes/), at MIT, under the direction of Rosalyn Picard: like Blobworld, Foureyes segments images and analyzes the features of segments, but unlike Blobworld, Foureyes allows the user to apply labels to each segment, and then, instead of using a single model (the Blobworld representation) for matching, it consults "a 'society of models' among which it selects and combines models to produce a labeling" that is extrapolated to other parts of other images in the system. It also allows the user to correct mistaken labelling of segments, and it attempts to learn from those corrections.

Based on these examples, and what works or doesn't work in them, it seems clear that segmentation is key in image-searching (as it is in natural language processing), that systems which share their representations with users are superior to those that don't, and that systems that allow and extrapolate from user feedback are best of all. In short: image-based image discovery tools should deduce rather than impose a preliminary analysis, should tell us what they're doing, and should learn from what we do with the results they give us. This might well be true of all disovery tools, for that matter.
Finding text through images:
If finding images using other images seems intuitive, finding text through images seems equally counter-intuitive, and yet there are a number of examples. Even before computers came along, machines like the Hinman collator (which uses electrical lights and mirrors to"converge" two texts into one) have been used to expose textual variants. Such machines take advantage of our ability to see patterns and variations in patterns, in effect using that to bypass the text's semantic distractions. In the digital library, we have seen scholarly experiments (such as David Gants' at UVa) using animated digital images to achieve similar ends. But there are also more familiar examples, including the fundamental elements of desktop computing with its hierarchical folders and icons, or the more recent but visually similar modeling of the hierarchy of elements within documents (in the Document Object Model, for example, or in an SGML tree). Optical character recognition counts as a kind of image-based text discovery, though in practice it's usually encountered in the context of text-based image discovery, when OCR'd text is the hidden data behind the page-image we get as a search result.
The same field of document analysis/computer vision research that produced OCR technology also sometimes deals with the automated analysis of page-layout, but I'm not aware of any tools that give us direct access to the spatial (and therefore essentially visual and mathematical) as opposed to linguistic (and therefore essentially aural and semantic) qualities of a page combining text with image. Analysis of the presentational aspects of a printed page is important if one considers that not all information in texts is textual: search engines already know this, because they give more weight to words that appear in <title> tags, or near the beginning of the body of the document. Tools that provide access to the visual aspects of textual objects could have significant and obvious applications in bibliographical study and textual editing, but equally significant though less obvious applications in media studies, cultural studies, and the many disciplines that deal with materials in manuscript form.
The problem of image-based text searches only gets more difficult and interesting as new natively digital technologies such as Flash come along: have a look at any of the examples in the gallery at the recent Flash conference in San Francisco (http://www.flashforward2000.com/), say for example Todd Purgason's site design for Lundstrom and Associates, at http://www.lundstromarch.com/000-00_set.html:

What will we do when we need to search for text that we remember as having popped up in one of those little boxes, or when we need to find text in three and four dimensions, text that moves in space and time?
Even now, traditional scholarship could also use higher-order text-modeling tools, which would provide a bird's-eye view of the distribution and clustering of different elements within a text. I can show you one such example at IATH, in a searchable SGML text of Dante's Inferno (http://urizen.village.virginia.edu/hell/), that returns results in the form of a three-dimensional model of the entire text of the poem, with search results distributed spatially to represent their distribution in the linear text, and color-coded by type.


This kind of image-based text searching has a great deal of potential, as does 3D information modeling more generally. As the digital library becomes the information universe, or vice-versa, we will have to have these bird's eye views simply to find our way around in extremely large collections. For various examples of what such an experience might look like, and why we might need these tools, have a look at the Cybergeography site, at http://www.cybergeography.org/atlas/atlas.html.
As we look at these examples, we should consider the problems and possibilities that will arise when scholars are no longer searching for pages about pages, but are searching across media in multi-dimensional information spaces.
Other Primitives:
In other contexts, I have complained that the digital library currently offers us little more than searching and browsing; in this discussion, I haven't advanced much beyond that myself, though I have tried to suggest ways in which searching might develop into higher-order tools like the ones we've just been discussing. Still, there are certainly important scholarly primitives other than "discovery," and these others certainly apply to scholarly uses of text and image in the humanities. Comparison, for example--it's one of the most fundamental scholarly moves. We compare texts to other texts in order to create scholarly and critical editions, or in order to uncover inconsistencies of content, or in order to speculate on vectors of textual transmission, and so on; we compare images to other images in order to understand the process of composition, or determine authenticity, or derive aesthetic judgments, etc.. We compare and cross-reference text and image every day in navigating scholarly as well as popular allusions, or even reading captions. The Blake Archive has a feature in its soon-to-be released version 2.0 that will make stunningly clear the importance of the simplest kinds of comparison: when you can find your way through a hierarchical information structure to a particular plate in a particular work of Blake's, and then ask to cut across the hierarchy and be presented, in one window, with every other printing of that plate in every other edition of that work, the value of simply comparing like objects is immediately obvious.

Likewise with the simple action of annotation: it's what we do every day in the margins of the books we read, what we do on our students papers, what we do when we review the work of a colleague or revise our own writing. It's such a simple thing, and yet the best computer-based implementations of this are still intolerably clumsy.
Representation is another fundamental scholarly activity poorly supported in digital libraries. Representation means not just the ability to convey digital surrogates, but the ability to express a structured understanding of a body of knowledge, propose competing expressions, and manipulate, cross-reference, and illustrate those expressions. The individual electronic text, the individual digital image, isn't generally the level at which this activity comes into play: rather, it arises in the construction of collections, in the building of editions, and in designing the underpinnings of long-term digital scholarly projects. It's the most valuable, most difficult, most interesting part of digital scholarship, in my view, and its products (database schema, SGML DTDs, and the like) are the distilled fruit of many hours, days, months, or years of scholarly and technical labor--and yet we haven't a clue, yet, how to collect, catalogue, index, or navigate such representations.
Libraries?
Finally, there's a question. "Finding" or discovery is most of what libraries have traditionally supported ("keeping" or preservation is a lot of the rest of it, and the rationale for doing that generally also has to do with finding, in the future). Do we expect libraries to continue to be (or perhaps, to become once again) the most important finding aids for digital information? If so, how do we think that will happen? And will libraries support these other activities, from comparison to annotation to representation (which could include authoring, collaboration, and publishing)? If so, will they also collect and preserve and make it possible to find these comparisons, annotations, and representations, or will they simply provide a place where scholars can sketch them, share them, and scratch them out or pass them on? The library is already, in my university, becoming a laboratory for the humanities in a way that it hasn't been for a long time. That laboratory function, with all its expensive and messy creation, may be a larger part of the library's future than it has been of its past. And I think there's little doubt that libraries will continue to be important keepers of information: I don't see any other institution out there likely to do that. But whether libraries retain the important function of helping us find information depends, I think, on whether they take seriously the importance of ready access to boundless collections--not that this is the only kind of access that matters, but because it is almost always the first kind that does, even for the scholar.